[ 03 / the glass ]
Many models.
One pane of glass.
A coder model on :8000, a vision model on :8001, embeddings on :8002 — all launched, monitored, and stopped from one screen. These are real screenshots, not mockups.
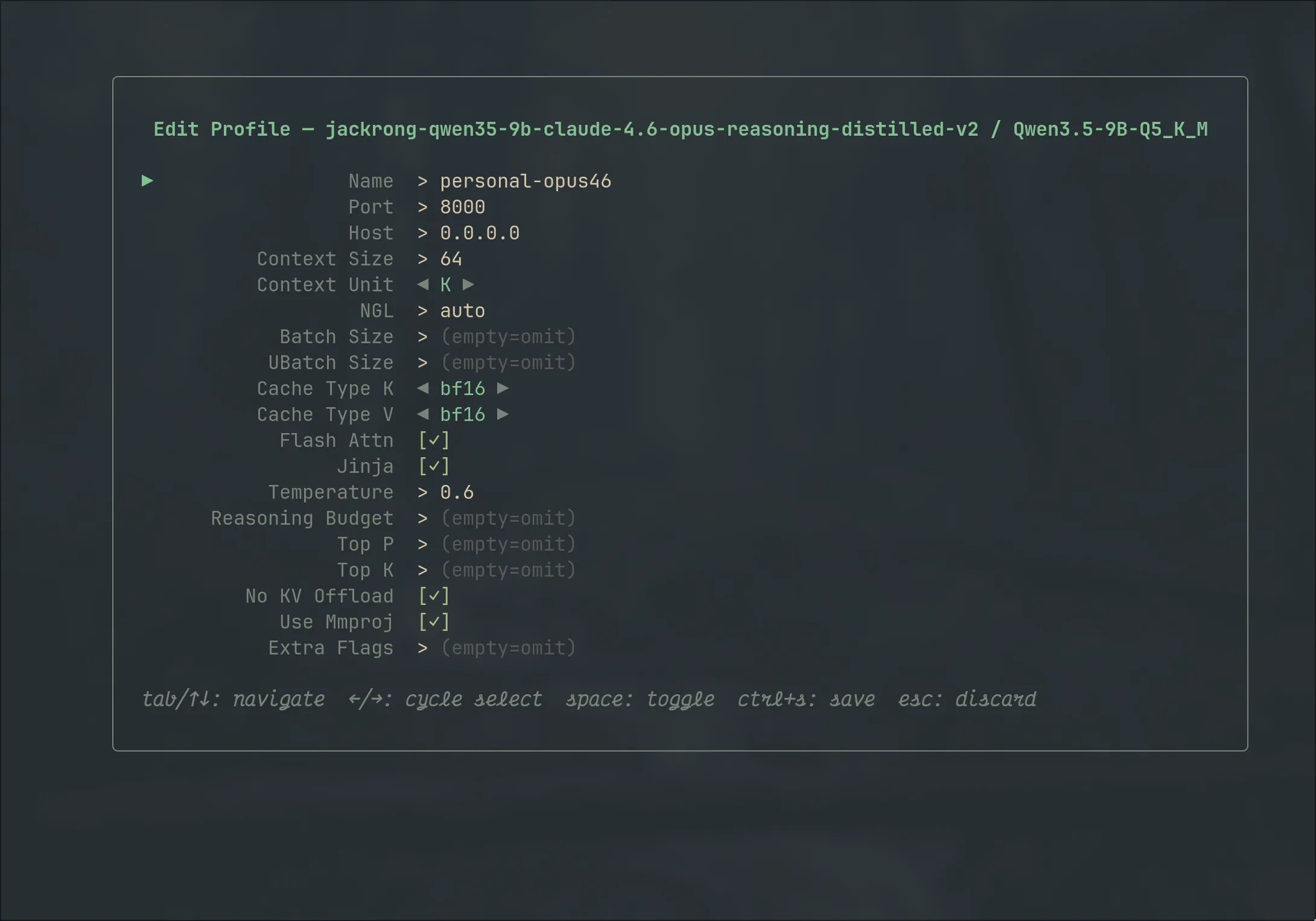
3.1
Configure once,
Configure once,
launch forever
Context size, GPU layers, KV-cache types, flash attention, sampling, extra flags — the editor exposes every knob with smart pickers, then remembers all of it. Relaunch is one keypress.
tab navigate · space toggle · ctrl+s save
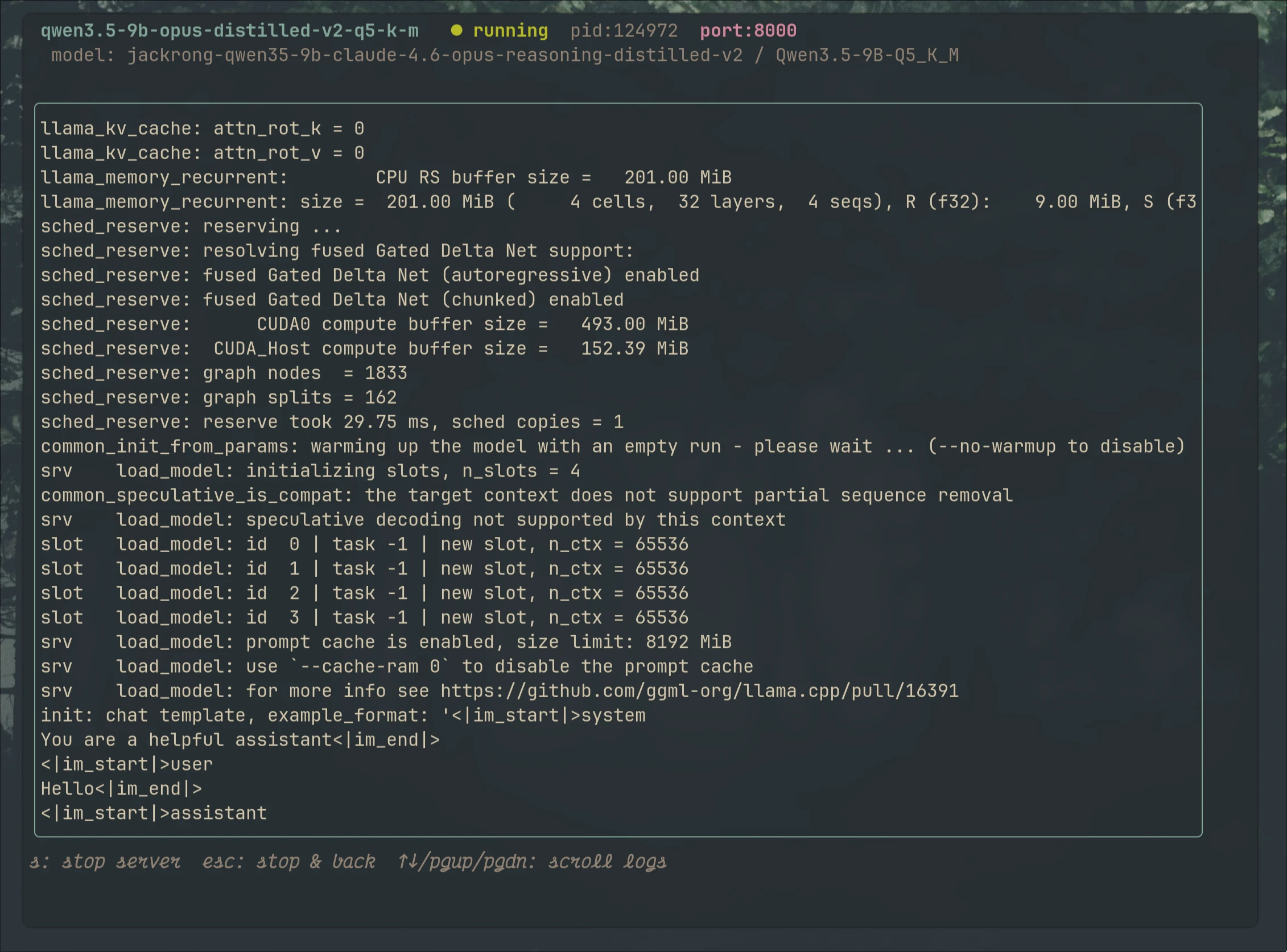
3.2
Watch inference
Watch inference
happen live
Per-run status, endpoint, uptime, and tokens-per-second. System and per-model CPU, RAM, and VRAM telemetry. Scrollable server logs. No tmux splits, no second monitor.
s stop · c clear logs · esc back